The Slowest Quicksort
Writing the slowest quicksort implementation, for science!
Published 2019-11-27 | 17 Minutes Long | 4410 WordsQuicksort is a sorting algorithm. It works in three main steps:
- Pick an element from the array (Called the pivot)
- Rearrange the array so that all the elements with values less than the pivot come before the pivot, while all elements with values greater than that of the pivot come after the pivot, leaving the pivot in its final position. This operation is referred to as the ‘partition’
- Recursively apply the same sequence to the two sub-arrays, and every sub-array they make
Here’s the algorithm in a python translation of the pseudocode lovingly provided by this wikipedia article:
def quicksort(array, low, high):
if low < high:
# Choose a pivot
pivot = partition(array, low, high)
# Sort the lower sub-array
quicksort(array, low, pivot - 1)
# Sort the higher sub-array
quicksort(array, pivot + 1, high)
# Return the sorted array
return array
def partition(array, low, high)
pivot = array[high]
i = low # Will store the eventual pivot point
# For each element in the sub-array
for j in range(low, high):
# If the item is less than the pivot
if array[j] < pivot:
# Swap the i'th and j'th item
array[i], array[j] = array[j], array[i]
# Increment i
i += 1
# Swap the highest element and the i'th element
array[i], array[high] = array[high], array[i]
# Return the pivot point
return i
To sort the entire array, simply call quicksort(array, 0, len(array) - 1). Normally, quicksort makes \(O(n \log n)\) comparisons where \(n\) is the number of items, but in the worst case scenario it can require \(O(n ^ 2)\) comparisons. This is comparable to both heap sort and merge sort, which both make \(O(n \log n)\) comparisons in both the best and worse case scenarios. However, quicksort still preforms an average of two to three times faster than the competition. Quicksort’s good performance is why I chose it to become exactly what it’s not supposed to be: slow.
With the background of what quicksort is, let’s move on to making it in Rust. Here’s a really basic quicksort I threw together:
fn quicksort(mut vec: &mut Vec<usize>, low: usize, high: usize) {
if low < high {
// Choose a pivot
let pivot = partition(&mut vec, low, high);
// Sort the lower sub-array
quicksort(&mut vec, low, pivot.saturating_sub(1));
// Sort the higher sub-array
quicksort(&mut vec, pivot + 1, high);
}
}
fn partition(vec: &mut Vec<usize>, low: usize, high: usize) -> usize {
let pivot = vec[high];
let mut i = low;
// For each element in the sub-array
for j in low..high {
// If the item is less than the pivot
if vec[j] < pivot {
// Swap the i'th and j'th item
vec.swap(i, j);
// Increment i
i += 1;
}
}
// Swap the highest element and the i'th element
vec.swap(i, high);
// Return the pivot point
i
}
So, this is reasonably efficient code. It operates entirely off of mutable references so zero allocation takes place, only copying values from one place in memory to another, along with some really simple comparisons. All in all, it’s a good algorithm. The benchmarks put this algorithm at a solid average of 7.7964 milliseconds to sort a 100,000 element long array of random integers, which is pretty fantastic for 34 lines of code.
Now, in most articles, this is where I would tell you that this is alright, but we can do better. However, as you might have guessed by the title, this article is not about improving performance. The first strategy of reducing performance we’ll be using is abusing indirection. Rust’s Vec is just a heap-based array, so the layout of the Vec we used in the normal implementation is something like this:
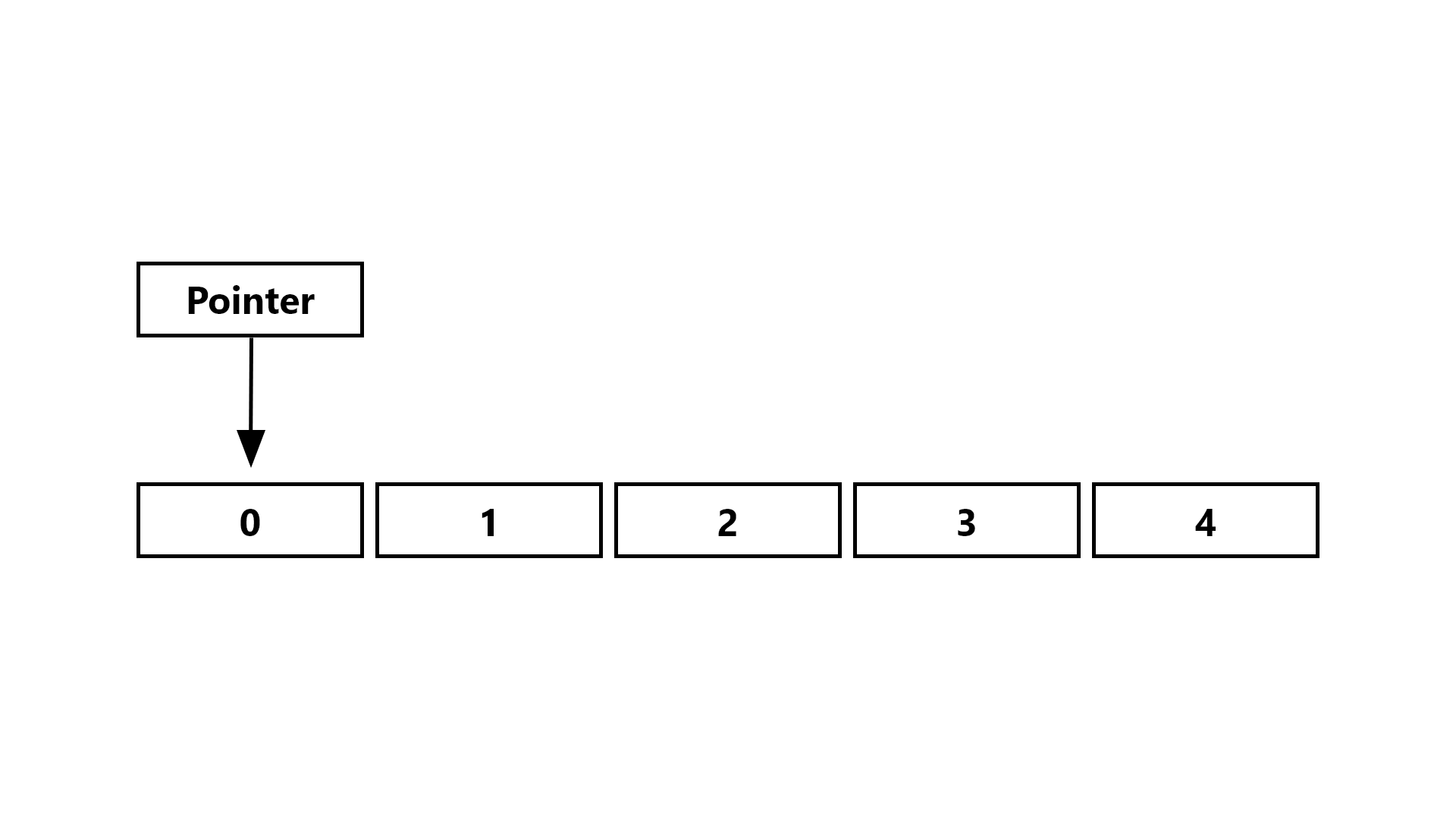
So to access an element in the vector, you simply take the pointer to the vector and offset it by n * size_of::<Element>() where n is the index of the element you want to access. This is a pretty efficient system, but we can do worse. Accessing a pointer is decently expensive on a computer, so maximizing pointer accesses (Or indirection) will net us a loss of performance. So, how do we maximize indirection when the vector only requires one level of it? By storing the actual value on the heap, but then storing the value’s pointer in the vector, turning our normal vector into a Vec<Box<T>>. Fortunately, we don’t have to stop with one box, we can (Theoretically) keep adding boxes forever, but after a while it gets rather absurd, so let’s stick to ‘just’ 3, making our vector a Vec<Box<Box<Box<T>>>>. The really fantastic thing about (ab)using boxes is that we don’t just have to focus on the items contained in the vector, we can also box up the vector itself, bringing our grand total to Box<Box<Vec<Box<Box<Box<T>>>>>> Using this monstrosity of a type means that each access to an element will require 6 pointer dereferences and accessing the vector itself will require 2 pointer dereferences, making our vector layout look like this:
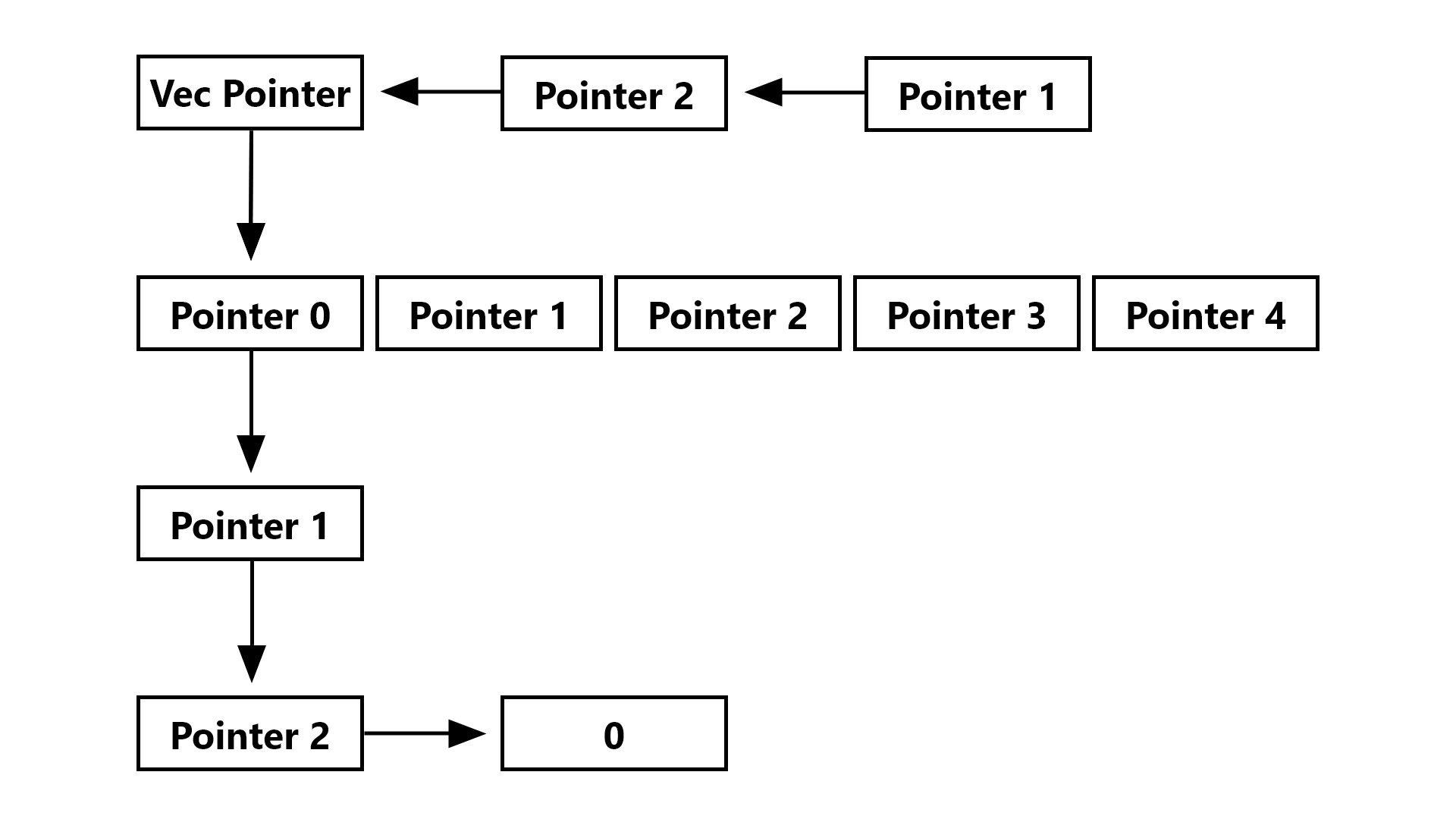
With our new strategy of indirecting pointers to the moon and back, let’s see our new code:
fn quicksort(
mut vec: &mut Box<Box<Vec<Box<Box<Box<usize>>>>>>,
low: Box<Box<Box<usize>>>,
high: Box<Box<Box<usize>>>,
) {
if low < high {
// Choose a pivot
let pivot = partition(&mut vec, low.clone(), high.clone());
// Sort the lower sub-array
quicksort(
&mut vec,
low.clone(),
Box::new(Box::new(Box::new((***pivot).saturating_sub(1)))),
);
// Sort the higher sub-array
quicksort(&mut vec, Box::new(Box::new(Box::new(***pivot + 1))), high);
}
}
fn partition(
vec: &mut Box<Box<Vec<Box<Box<Box<usize>>>>>>,
low: Box<Box<Box<usize>>>,
high: Box<Box<Box<usize>>>,
) -> Box<Box<Box<usize>>> {
let pivot = vec[***high].clone();
let mut i = low.clone();
// For each element in the sub-array
for j in ***low..***high {
// If the item is less than the pivot
if vec[j] < pivot {
// Swap the i'th and j'th item
vec.swap(***i, j);
// Increment i
***i += 1;
}
}
// Swap the highest element and the i'th element
vec.swap(***i, ***high);
// Return the pivot point
i
}
Wow, those are quite the function signatures. Other things to note are all the dereferences (*) and the re-boxing of some integers, this just happens because we are manually walking down that path of pointers. If this were any other language, we’d be smothered in dereferences, but Rust’s auto-dereferencing rules make our crime against silicon much easier to look at. The benchmarks for this quicksort come in at 173.18 milliseconds. Not bad for a first try, but we can still do much worse.
Now we can move on to everyone’s favorite subject, concurrency. For most people, lockless concurrency is the holy grail of performance, allowing a program to soar on the wings of multi-threaded greatness. However, we won’t be soaring today as the type of concurrency we’ll be shooting for would be better as lockful. If you aren’t familiar with multi-threaded programming, you might not know what a lock is. In short, a lock is a mechanism that only allows one thread to access a resource at a time. The way that we’ll be leveraging this is to make every thread wait a really long time before it’s able to do a little bit of work, and to hopefully make the combined threads spend more time fighting each other for access to data than they actually spend using the data. Additionally, making/using threads isn’t a zero-cost function, as context switching are rather expensive in terms of performance. In Rust, using the aforementioned locks is easy, all you do is wrap your data in a Mutex and an Arc for reference counting, giving you an Arc<Mutex<T>>. The arc also gives us a little boost in the amount of work we’re required to do, as it forces an increment/decrement operation every time that the data is accessed. The easy thing to do would be to simply wrap the boxed up nightmare from earlier in the arc and mutex, but we can do worse. Since sometimes individual values are being moved around, why don’t we wrap each value in it’s own arc and mutex? Following this series of bad decisions, we have a Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<T>>>>>>>>>>. For now, let’s try this locking strategy without introducing threads into the mix:
pub fn quicksort(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
) {
if *low.lock().unwrap() < *high.lock().unwrap() {
// Choose a pivot
let pivot = partition(vec.clone(), low.clone(), high.clone());
// Sort the lower sub-array
quicksort(
vec.clone(),
low.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(
pivot.saturating_sub(1),
))))),
);
// Sort the higher sub-array
quicksort(
vec.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(pivot + 1))))),
high,
);
}
}
fn partition(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
) -> usize {
let mut i = *low.lock().unwrap();
// For each element in the sub-array
let (l, h): (usize, usize) = (*low.lock().unwrap(), *high.lock().unwrap());
for j in l..h {
let piv: usize = *vec.lock().unwrap()[*high.lock().unwrap()].lock().unwrap();
let left: usize = *vec.lock().unwrap()[j].lock().unwrap();
// If the item is less than the pivot
if left < piv {
// Swap the i'th and j'th item
(*vec.lock().unwrap()).swap(i, j);
// Increment i
i += 1;
}
}
// Swap the highest element and the i'th element
let temp_high = *high.lock().unwrap();
vec.lock().unwrap().swap(i, temp_high);
// Return the pivot point
i
}
Unsurprisingly, adding tons of overhead to each and every operation does slow the program down, making this implementation clock in at 598.37ms per sort, giving us a regression of 590.57ms. Not bad for just a little type mangling, if I do say so myself. Before we jump head-long into the incredibly threaded example, we’ll use a thread pool, which is just a method of distributing the work of a process across a set number of threads. For this example, I’ll be using threadpool:
pub fn quicksort(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
pool: ThreadPool,
) {
// Clone the threadpool (Only clones pointers) so we can move it into the threadpool closure
let p = pool.clone();
// Create a channel so we know when the algorithm is done
let (send, recv) = mpsc::channel::<()>();
// Execute the function in the threadpool
pool.execute(move || {
if *low.lock().unwrap() < *high.lock().unwrap() {
// Choose a pivot
let pivot = partition(vec.clone(), low.clone(), high.clone());
// Sort the lower sub-array
quicksort(
vec.clone(),
low.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(
pivot.saturating_sub(1),
))))),
p.clone(),
);
// Sort the higher sub-array
quicksort(
vec.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(pivot + 1))))),
high,
p.clone(),
);
}
// The calculation is finished, so tell the main thread
send.send(()).unwrap();
});
// Blocks the thread until the calculation is finished
recv.recv().unwrap()
}
fn partition(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
) -> usize {
let mut i = *low.lock().unwrap();
// For each element in the sub-array
let (l, h) = (*low.lock().unwrap(), *high.lock().unwrap());
for j in l..h {
let pivot_value = *vec.lock().unwrap()[*high.lock().unwrap()].lock().unwrap();
let j_value = *vec.lock().unwrap()[j].lock().unwrap();
// If the item is less than the pivot
if j_value < pivot_value {
// Swap the i'th and j'th item
(*vec.lock().unwrap()).swap(i, j);
// Increment i
i += 1;
}
}
// Swap the highest element and the i'th element
vec.lock().unwrap().swap(i, *high.lock().unwrap());
i
}
Throughout the incredibly scientific process of hours of debugging, I found that the minimum amount of threads to avoid a deadlock when working on a 100,000 element array was 40, so that’s what all the benchmarks are with. Even so, benchmarking still took over 2 hours, so rest assured when I say that this is one really slow implementation, with a time of 2097.6ms per sort.
Unfortunately for my poor computer, this isn’t where I’m stopping. Now we’re gonna start swinging hard by spawning a new, separate OS thread for each and every call to quicksort. After all this reckless programming is finished, the dust clears on this code:
pub fn quicksort(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
) {
// Create a channel so we know when the algorithm is done
let (send, recv) = mpsc::channel::<()>();
// Spawn the thread that will do all the work
thread::spawn(move || {
if *low.lock().unwrap() < *high.lock().unwrap() {
// Choose a pivot
let pivot = partition(vec.clone(), low.clone(), high.clone());
// Sort the lower sub-array
quicksort(
vec.clone(),
low.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(
pivot.saturating_sub(1),
))))),
);
// Sort the higher sub-array
quicksort(
vec.clone(),
Box::new(Box::new(Box::new(Arc::new(Mutex::new(pivot + 1))))),
high,
);
}
// Notify the main thread that the calculation is finished
send.send(()).unwrap();
});
// Block the thread until the calculation is finished
recv.recv().unwrap()
}
fn partition(
vec: Arc<Mutex<Box<Box<Vec<Box<Box<Box<Arc<Mutex<usize>>>>>>>>>>,
low: Box<Box<Box<Arc<Mutex<usize>>>>>,
high: Box<Box<Box<Arc<Mutex<usize>>>>>,
) -> usize {
// Create a channel so we can get the pivot point
let (send, recv) = mpsc::channel::<usize>();
// Spawn the thread that will do all the calculation
thread::spawn(move || {
let mut i = *low.lock().unwrap();
// For each element in the sub-array
let (l, h): (usize, usize) = (*low.lock().unwrap(), *high.lock().unwrap());
for j in l..h {
// If the item is less than the pivot
let piv: usize = *vec.lock().unwrap()[*high.lock().unwrap()].lock().unwrap();
let left: usize = *vec.lock().unwrap()[j].lock().unwrap();
if left < piv {
// Swap the i'th and j'th item
(*vec.lock().unwrap()).swap(i, j);
// Increment i
i += 1;
}
}
// Swap the highest element and the i'th element
let temp_high = *high.lock().unwrap();
vec.lock().unwrap().swap(i, temp_high);
// Return the pivot point
send.send(i).unwrap();
});
// Get the pivot point and return it
recv.recv().unwrap()
}
The gist of this rather painful code is that we’re acquiring a lock on data on each and every access, instead of keeping the lock in scope and doing all our business before releasing it, which means that more and more work is being done. The recursive nature of this algorithm also means that as time goes on, more and more threads are spawned, leading to even more competition over the data, which means more and more waiting for other threads to finish. However, the only slight downside of this method is that all our efforts in the allocation section are gone, since for the maximum performance loss we need every thread to be operating off of the same piece of data (Ignore the clone()’s, they just clone the pointer to the data). This has the potential to be the absolute worst algorithm in this article save for one fatal flaw. It shares problem that the previous cloning example has, except with threads. This horrendous implementation takes a whopping 24,429ms to sort.
Another expensive operation is the allocation of memory, which we do very little of any two quicksorts, but that can be changed. In this one, I tried to make as many new/cloned vecs as possible, so here’s the snippet:
fn quicksort(
vec: &mut Box<Box<Vec<Box<Box<Box<usize>>>>>>,
low: Box<Box<Box<usize>>>,
high: Box<Box<Box<usize>>>,
) {
if low < high {
// Choose a pivot
let mut v = vec.clone();
let pivot = partition(&mut v, low.clone(), high.clone());
// Sort the lower sub-array
let mut v_low = v.clone();
quicksort(
&mut v_low,
low.clone(),
Box::new(Box::new(Box::new((***pivot).saturating_sub(1)))),
);
// Sort the higher sub-array
let mut v_high = v_low.clone();
quicksort(
&mut v_high,
Box::new(Box::new(Box::new(***pivot + 1))),
high,
);
*vec = v_high;
}
}
fn partition(
vec: &mut Box<Box<Vec<Box<Box<Box<usize>>>>>>,
low: Box<Box<Box<usize>>>,
high: Box<Box<Box<usize>>>,
) -> Box<Box<Box<usize>>> {
let mut v = vec.clone();
let pivot = v.clone()[***high].clone();
let mut i = low.clone();
// For each element in the sub-array
for j in ***low..***high {
// If the item is less than the pivot
if v[j] < pivot {
// Swap the i'th and j'th item
v.swap(***i, j);
// Increment i
***i += 1;
}
}
// Swap the highest element and the i'th element
v.swap(***i, ***high);
*vec = v;
// Return the pivot point
i
}
This example is interesting to me because it is the absolute worst thing ever. Each time any of the functions are called, it clones the entirety of the array. While this might seem less than ideal, the true implications become clear once you realize that the function is recursive. This means on each and every iteration, yet another vector is cloned, leading to an exponential increase of memory usage. This implementation is so wildly inefficient that I couldn’t even benchmark it, as the estimated time to benchmark was over 460 days. Running a single benchmark showed that the time for a single sort was a little over 2 hours. If anyone has the patience to run a full benchmark, please email me the criterion files.
So, what was the point of all of this? Well, by seeing how to make a program run slow, we also catch a glimpse into what not to do, albeit in an exaggerated way. While what I’ve shown may seem far-fetched, the layers of boxes are not always plain, as they might be hiding behind and within structs and enums, just waiting for the wrong scenario to make your application grind to a halt. So, don’t abuse boxes and threading and don’t re-allocate and clone willy-nilly, even if it is the easiest option sometime. Small corner cuts don’t seem like a big deal for smaller projects, but once you make something big people will eventually use it for something critical. So contribute to the ecosystem of safe software that Rust enables us to make, and make it well; Lay a foundation for others to build upon. Go forth and create.
All code used in this article is stored here, including the code used for benchmarking.
Full Benchmark Results
All benchmarking was done on a Ryzen 7 1700 at stock clock speed. The dataset was a 100,000 element long vector of randomly generated 64bit integers and benchmarks were recorded using Criterion.rs.
Time per Sort (Milliseconds)
| Implementation | Best | Average | Worst |
|---|---|---|---|
| Normal | 7.7705 | 7.7964 | 7.8256 |
| Boxed | 172.72 | 173.18 | 173.67 |
| Locked | 592.71 | 598.37 | 604.79 |
| Threadpool (40 Threads) | 2086.0 | 2097.6 | 2113.1 |
| Threaded | 24,400 | 24,429 | 24,461 |
| Cloning | N/A1 | 7,926,5682 | N/A1 |
1Unable to be benchmarked
2Estimated time
CPU Cycles per Sort
| Implementation | Best | Average | Worst |
|---|---|---|---|
| Normal | 24,040,958 | 24,070,177 | 24,105,755 |
| Boxed | 518,485,370 | 520,018,311 | 521,567,220 |
| Locked | 1,683,092,813 | 1,689,905,530 | 1,690,279,314 |
| Threadpool (40 Threads) | 6,300,137,521 | 6,338,662,712 | 6,386,263,913 |
| Threaded | 77,389,863,516 | 79,855,437,596 | 82,441,212,041 |
| Cloning | N/A1 | N/A1 | N/A1 |
1Unable to be benchmarked