Intro to DDlog
A dive into using Differential Datalog
Published 2020-11-13 | 11 Minutes Long | 2342 WordsDatalog is a declarative programming language. For those who don’t know,
a declarative language is a language that
“expresses the logic of a computation without describing its control flow”. That’s a bit daunting of a definition,
so I prefer to say it’s defining what a program does instead of how it does it. In “normal” languages (imperative,
functional, etc) you give the computer a sequence of instructions to follow, the standard “if this, then that” we’re
all so familiar with. This leads to a relatively lower-level program, as we’re telling the computer exactly what it
should do at any time. The underlying language may take liberties with how this plays out, but in the end it’s doing
what you told it to. Contrasting this, the actual how’s of a declarative program’s execution is left entirely up to
the implementation, all you give it is the lose framework of what you want to happen and it fills in the gaps.
Differential Datalog (also known as DDlog) is one such
implementation, with the notable difference from other datalog flavors that it compiles to
Differential Dataflow, a data-parallel framework for
processing large amounts of data incrementally (See timely and differential-dataflow’s documentation for more in-depth
information on that side of things).
That’s a bit to wrap your head around, so lets look at a small example. Here’s the setup: we have a list of graph edges and we want to find all paths through the graph. Here’s the code:
input relation Edge(x: u32, y: u32)
output relation Path(x: u32, y: u32)
Path(x, y) :- Edge(x, y).
Path(x, y) :- Edge(x, z), Path(z, y).
To people who know with languages like Prolog, this probably looks really familiar since graphs are a place where declarative languages really shine. However, to those of us who have never used a logic language this looks daunting, so let’s break it down piece by piece
input relation Edge(x: u32, y: u32)
This is our (aptly named) input relation, it’s what is fed into the program by the user. Users interact with ddlog
programs through a series insert/update/delete/modify instructions that are very reminiscent of database
directives. For this input relation in particular, we’ve given it the name Edge and it contains two fields:
x which holds an unsigned 32bit integer and y which also holds an unsigned 32bit integer. Let’s use this as
our graph program’s input (written in ddlog’s dat format)
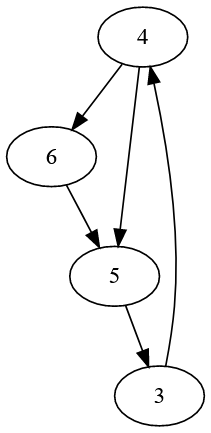
insert Edge(4, 6),
insert Edge(6, 5),
insert Edge(4, 5),
insert Edge(5, 3),
insert Edge(3, 4).
This maps out to a very simple little graph
Next up we have an output relation named Path
output relation Path(x: u32, y: u32)
Output relations are how ddlog communicates with the outside world, they’re automatically (and incrementally) updated when facts they depend on change. What’s a fact? Well, I’m glad you asked! The bulk of ddlog programs are made up of facts and rules (referred to collectively as a clause). A fact is just that, it’s a truth (within the context of the program, I’ll get into that later) that has been derived from the given rules
Path(x, y) :- Edge(x, y).
^^^^^^^^^ ^^^^^^^^^
fact rule
In layman’s terms this clause is saying “for every Edge with an x and a y, create a Path with that x and y”
and it does exactly that, looking at the contents of the Path relation shows us an identical copy of what we gave it
as input
Path(4, 6).
Path(6, 5).
Path(4, 5).
Path(5, 3).
Path(3, 4).
Then comes the second rule, and this is where ddlog throws us a curve ball. This isn’t a normal rule, this is a recursive rule
Path(x, y) :- Edge(x, z), Path(z, y).
Before I explain what’s going on here, there’s a few new things going on that I want to point out. First is a new piece
of syntax, the comma between Edge(x, z) and Path(z, y). This is a logical AND of sorts, each successive rule applies
filters to the ones before it. The second thing is that both the Edge rule and the Path rule have a z field, which
looks kinda weird at first glance. What this is doing is first declaring z as the second field of the Edge relation
and then only selecting the values from Path where its first field is the same as the z from the Edge. Breaking
back down into english, this clause is saying “for every Edge with an x and z, select every Path where Path.x
is equal to z and take its y, then create a Path with the x from Edge and the y from Path”. The really neat
thing about recursive rules is that they will efficiently recurse to completion since every time a new Path is added,
more possible paths open up that need to be computed.
I didn’t mention this earlier, but vanilla Datalog is quite boring. It’s not turing complete and it lacks a lot of the more creature comforts of programming as well as vital things like negation. Normal Datalog is also untyped, which is a huge detriment to larger programs. DDlog solves both of these problems (and more) by allowing your ddlog programs to incorporate user-defined types, enums and functions. This makes programming in ddlog a lot more comfortable than a pure logic-based language, as well as more familiar.
To get a little more familiar with ddlog, let’s make a little program to grade students based off of their test scores. Our inputs will be the students who will each have a name (which we’ll assume is unique) and a series of grades, each connected to a student by name with the score they got on it. If a student has no test scores, they don’t have a grade in the class. Translated to ddlog we’d create these input relations and the corresponding output relation
input relation Student(name: string)
input relation Test(student: string, score: float)
output relation Grades(student: string, score: Option<float>)
First things first, what’s that Option<float>? Well, this is one of those enums I mentioned (which also takes a generic value).
Option is declared in ddlog’s standard library
and it looks like this
typedef Option<'A> =
None
| Some { x: 'A }
If you’re familiar with a functional language like ML or Haskell, this looks pretty familar. This is declaring the type Option
with the generic parameter 'A which has the None variant and the Some variant where the Some variant contains an instance
of the generic 'A. This is exactly the same as Rust’s Option or Haskell’s Maybe, it’s either something or nothing.
As a quick side note since I couldn’t figure out how to shoehorn it into this example, the syntax for defining ddlog structs
is very similar, we’ll make a more complex Test just to show it off
typedef Test = Test {
student: string,
possible_points: float,
earned_points: float,
curve_percentile: float,
}
That defines the Test struct with the student, possible_points, etc. fields. Structs can also have generics, the syntax
is the same as with enums. With that out of the way, we’re going to find all the students who have no test grades so we
can give them no grade
Grades(student, None) :-
Student(student),
not Test(student, _).
What we’re doing here is saying that for each student in the Student relation who has no test grades, their grade is None.
This uses negation,
another feature not part of standard datalog.
From there, calculating averages is pretty simple when you use the .group_by() operator
Grades(student, Some { score }) :-
Student(student),
Test(student, test),
var test_scores = test.group_by(student),
var score = test_scores.average().
Woah, that gave us a lot of new stuff all at the same time, so let’s take it piece by piece. First off we have Some { score }.
This is pattern matching, and is just a nice way of wrapping the score we get from the rules of the clause into an Option
package. Next up is var test_scores = test.group_by(student), our group_by clause I talked about earlier. What this does is
group each test by the given student. This will yield a Group<string, float> (defined in the ddlog std) which I’ll address
later that we then store into the test_scores variable that we declare with var test_scores =. Lastly we have
var score = test_scores.average() which calls the .average() function on the test_scores variable before storing it into
score.
What is this .average() function we just called, and where did it come from? Well, we actually declared it ourselves! It’s a
pretty standard function for finding the average of a bunch of float values, here’s the code
function average(scores: Group<string, float>): float {
// Sum up the test scores, then divide that by the number
// of test scores we got
scores.group_sum() / scores.count() as float
}
This defines the function average which takes in a Group of strings and floats and returns one single float, pretty simple.
“Hold up a moment”, I hear some of you saying “that declares a free function, but you called it like a method, that can’t
be right!”. Well fear not reader, because ddlog has universal function call syntax which is a big and fancy name for “you can call free functions using method syntax”. This means
both test_scores.average() and average(test_scores) are equally valid, so what you choose to use is entirely up to
what you feel more comfortable with.
Full DDlog code
// intro.dl
input relation Student(name: string)
input relation Test(student: string, score: float)
output relation Grades(student: string, score: Option<float>)
Grades(student, None) :- Student(student), not Test(student, _).
Grades(student, Some { score }) :-
Student(student),
Test(student, test),
var test_scores = test.group_by(student),
var score = test_scores.average().
function average(scores: Group<string, float>): float {
scores.group_sum() / scores.count() as float
}
Now that we know about ddlog, lets see what’s working behind it. DDlog compiles to
Differential Dataflow
in the form of native Rust code. So, what’s so special about dataflow that makes it so well
suited for ddlog, and why should you care? Well, the specifics of dataflow are complicated,
but at a basic level it’s a framework for processing large amounts of data incrementally and
in parallel. It works by taking a set of inputs (represented in ddlog by input relations)
and producing a series of outputs (represented in ddlog by output relations). The really cool
part of this is that dataflow tracks the interdependence of all data within it and only
recalculates what strictly has to be. In a scenario where A is derived from B and C
from D, changes to the B relation will have no affect on C or D, meaning that the
absolute minimum amount of work has to be done in response to arbitrary changes. Not satisfied
with just being incremental, dataflow is also massively scalable both across a single computer
via threading and across networks as a distributed system. This also extends to DDlog, work on
D3log
(a distributed version of ddlog) is currently in-progress.
In addition to all this, ddlog is incredibly expressive. It’s statically typed which prevents bugs, it allows user-defined types and functions, it allows interop with arbitrary rust code and libraries you write and even breaking out of the ddlog environment to write raw dataflow code to express things that ddlog can’t.
This is the first in a series of ddlog posts, next I’ll be guiding you through actually using ddlog with Rust, then I’d like to talk about my work on RSLint implementing scope analysis on JavaScript code and my plans for code flow analysis and type checking JavaScript & TypeScript, all in ddlog.